This post is co-authored with Olha Hladka, a QA Engineer at QA Madness.
QA specialists familiar with test design techniques find it much easier to create efficient test suites. By employing a particular technique, we get guidelines on what to test and how to define test conditions. In other words, each test design technique helps to convert available data into efficient test cases.
In this post, you will learn about five commonly-used test design techniques that will help you ensure maximum test coverage and reduce time spent on testing activities.
Let’s start with the basics. Test design is a stage of the quality assurance process, during which we create test scenarios and outline the structure of testing activities for the project. A QA team decides on how to escalate test coverage with minimum effort.
The main purpose of the test design process is to structure QA routines so it becomes easier to keep track of the requirements coverage. We need test design:
What are test design techniques? They are strategies that help to write better test cases. The benefits of using test design techniques is an opportunity to create fewer tests while ensuring broad requirements coverage.
There are a dozen of test design techniques you can use, but let’s focus on the most popular ones:
The equivalent class partitioning and boundary value analysis are probably the most frequently black-box test design techniques since they aim to reduce the number of necessary test scenarios.
The equivalent class partitioning implies splitting test data into classes, where all elements are similar in some way. This technique makes sense only if the components are similar and can fit in a common group.
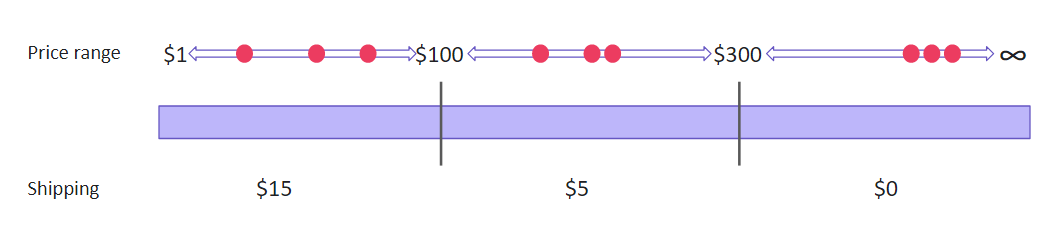
Choosing this technique means that we are going to test only a few values from every group. Remember that doesn’t guarantee that the rest of the values not covered by the tests will be bug-free. We only assume that using several elements from the group will be quite illustrative.
The equivalent class partitioning is a good solution for cases when you deal with a large volume of incoming data or numerous identical input variations. Otherwise, it might make sense to cover a product with tests more closely.
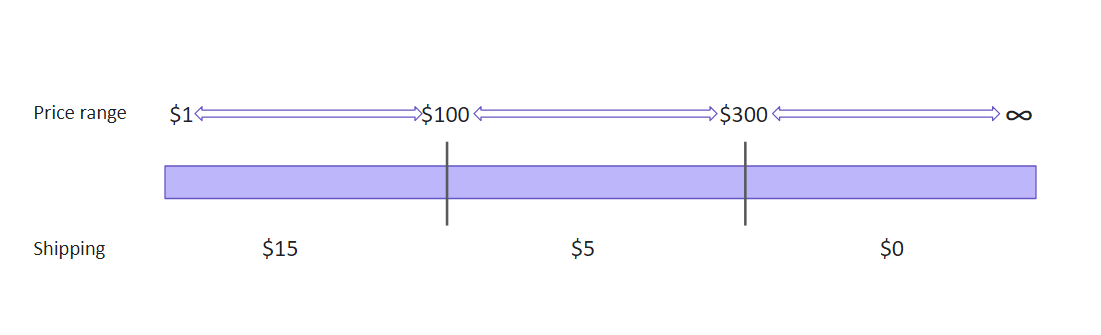
Let’s say, there is an online store that offers different shipping rates depending on a cart price. For example:
We have the following price ranges to work with:
If you use the equivalent class partitioning technique, you get three sets of data to test:
– valid boundary conditions: any price in the range from 1 to 99.99;
– invalid boundary conditions: any price below 1 or above 99.99;
– valid boundary conditions: any price in the range from 100 to 299.99;
– invalid boundary conditions: any price below 100 or above 299.99;
– valid boundary conditions: any price above 299.99;
– invalid boundary conditions: any price below 300.
So, we can just pick several numbers from each price range and assume that the rest of alike inputs will show the same results.
The boundary value analysis is similar to the previous technique. Some may even say it is based on the equivalent class partitioning. So what makes the boundary value analysis different?
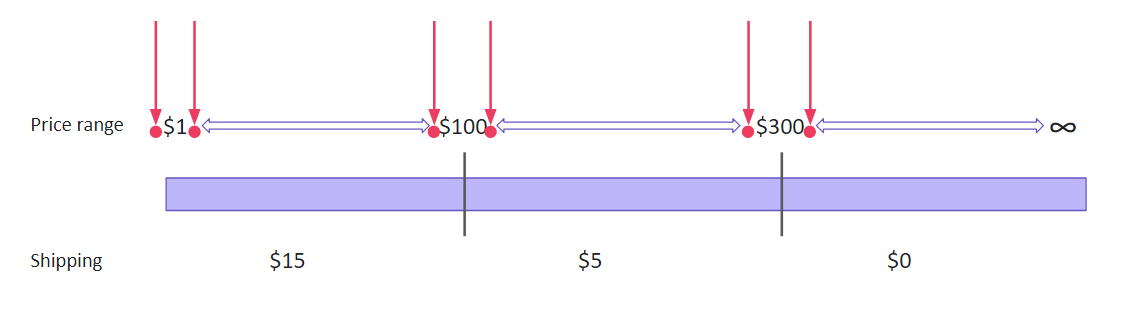
We still group data in equivalent classes but don’t test values from a particular class only. Instead, we check boundary values, those that are at the ‘borders’ of the classes. The same logic works perfectly for integration testing. We check smaller elements during unit testing, and on the next level, the errors are likely to pop up at the unit junctions.
Let’s take the previous scenario with varying shipping rates. We have the same data but a different approach to using it. Assuming that errors are the most likely to occur at the boundaries, we test only the ‘boundary’ numbers:
The state transition visualizes the states of a software system at different time frames and stages of usage. Visual information is simpler to perceive compared to verbal description. Therefore, the state transition allows you to come up with ultimate test coverage more quickly. This technique is effective for creating test suites for systems that have many state variations. It will be helpful if you test a sequence of events with a finite number of input options.
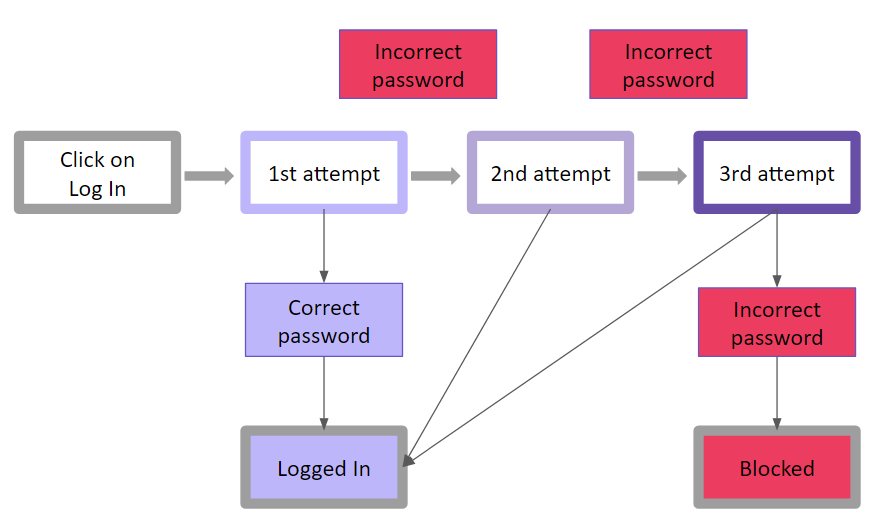
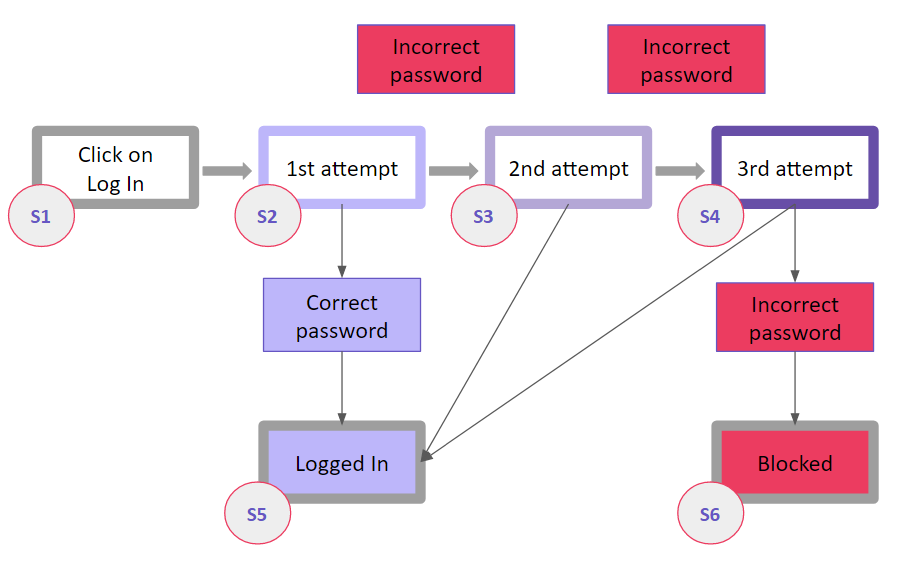
The simplest example of the state transition is visualizing logging into an account during web or mobile app testing. Let’s say, we are testing a system that offers a limited number of attempts to enter a correct password. If a user fails to enter a correct password, the system blocks the access (temporarily or permanently, it doesn’t matter now). A logic diagram would look like this:
Blocks of different colors designate specific states of the system. Let’s add the labels designating states, and we’ll get the following:
A chart like this makes it easier to match possible inputs with expected outputs. Having a visualization right in front of your eyes helps to keep a clear head and connect the states correctly. You can later arrange the data concisely and conveniently – for example, in a table to look up to during testing:
The pairwise testing is considered the most difficult and confusing of the five test design techniques. And there is a good reason for this. The pairwise testing is based on mathematical algorithms, namely combinatorics. It makes it possible to create unique pairs and test a huge amount of incoming data in different combinations, but the calculations might get complicated. To cover the maximum of features with test scripts that will require minimum time for testing, you need to match data correctly, combining pairs in a specific way based on the calculations.
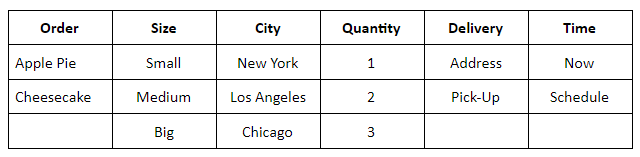
Let’s say, there is a network of bakeries selling apple pies and cheesecakes online. Each is available in three sizes – small, medium, and big. The bakery offers immediate and scheduled address delivery, as well as a pick-up option. The bakery works in three cities – New York, Los Angeles, and Chicago. Also, a user can order up to three items at a time.
If you want to test all possible inputs, that would be 2x3x3x3x2x2=216 valid order combinations. However, checking each of those would be unreasonable. Instead, you can arrange the variables in a way that will allow covering maximum scenarios.
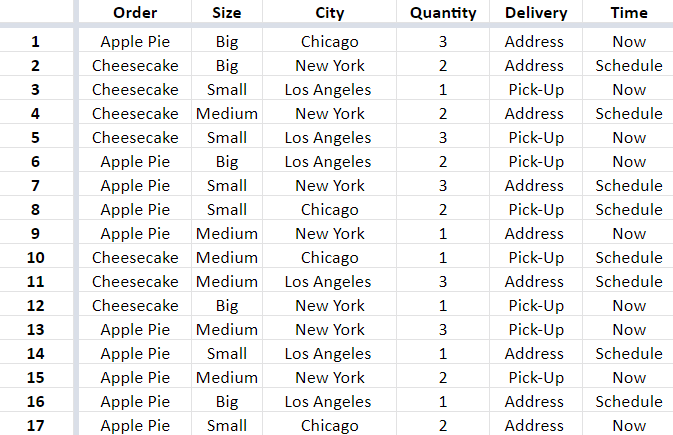
To do this, you’ll need to group the variables or use one of the tools that can do it for you. We used Pairwise Online Tool o create this example. As a result, we got 17 scenarios able to cover all 216 combinations. You can see the list of combinations below.
Error guessing is the most experimental practice of all, usually applied along with another test design technique. In error guessing, a QA engineer predicts where errors are likely to appear, relying on previous experience, knowledge of the system, and product requirements. Thus, a QA specialist is to identify spots where defects tend to accumulate and pay increased attention to those areas.
As a rule, QA engineers start with testing for common mistakes, such as:
The more experience a QA specialist has, the more error guessing scenarios they can come up with quickly.
A correctly chosen test design technique helps to use QA resources smartly. Very often, QA engineers need to combine several test design techniques to ensure the most effective coverage. The correct combination always depends on a specific project. Some specialists choose a particular approach intuitively, without referencing the theory much. Well, with years, you start to do some things reflexively 😉
It all depends on how you use it. Sorry to everyone looking for a simple…
Software accessibility is not optional. Inclusive digital experiences are required by governments. And they aren't…
Banking applications have become the essentials to have on our smartphones. Yet, with all the…
Accessibility testing evolved from a compliance exercise to a core component of user experience strategy.…
Browser compatibility testing explores whether websites and web applications function correctly across different browsers. It…
Financial technology has undergone a dramatic transformation in recent decades—or even in recent years. We've…
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}